I have some questions about acados i.c.w. ARM Cortex R-series. Not really close to implementing yet, rather looking ahead and being curious:
Is it expected that cross-compilation with target=generic will work for such systems now? In other threads, I have come across 32-bit open issues and required support for vectorized floating point instructions?
What kind of performance increase do BLASFEO and HPMPC achieve with ARM Cortex A-series specific implementations vs generic? Would those be easily transferrable to R-series processors?
I have also come across Arm Compiler for Linux | Arm Performance Libraries benchmark data – Arm Developer . The benchmark curves are interesting in that they achieve significant speedups w.r.t. BLAS for smaller size matrices, just as BLASFEO does. The ARM PL speedup looks huge though?! Can anyone provide a comparative statement? Could acados and/or its solvers be compiled against the ARM performance libraries for BLAS operations?
Apologies for the many questions, but it’s all so fascinating
first of all, welcome to the forum!
I’ll try to answer your questions below:
Unfortunately, 32-bit architecture are not supported by acados for now due to memory alignment issues: Support 32 Bit Architectures · Issue #599 · acados/acados · GitHub
I don’t see a clear connection to cross-compilation, but I am also not very familiar with that.
You can find some benchmarks of BLASFEO with ARM A-series processors here https://blasfeo.syscop.de/comparisons/
There are significant differences depending on which ARM A processor and which routine is used.
I don’t know how BLASFEO with ARM R-series performs. Maybe @giaf can elaborate a bit on this.
This ARM PL benchmark indeed seems interesting and the speedup huge. The Neoverse N1 is supposedly almost identical to A76, which @giaf has run BLASFEO on, so maybe he can also give some context here.
acados directly uses the BLASFEO API. Thus, in acados BLASFEO cannot be easily replaced out by another BLAS implementation.
Since you ask about target=generic, I expect that both HPIPM (replacement of HPMPC) and BLASFEO can be cross compiled and run on a ARM Cortex R core, and there should be no issues with 32-bit OS (e.g. they have already been run on 32-bit x86 and cross-compiled for Android). On the other hand, as Jonathan said, there are currently some issues in acados for use on a 32-bit OS.
For ARM Cortex A cores, the main performance difference between GENERIC and tailored targets is the explicit use of SIMD in assembly. Therefore, the speedup can range from rather small (e.g. ARMv7A in double precision where there is no vectorization possible) to rather large (e.g. ARMv8A in single precision has 4-wide vector instructions). Similar speed ups can be transferred to ARM Cortex R cores, but I am not familiar with them so I couldn’t tell now what are the vector capabilities of such cores).
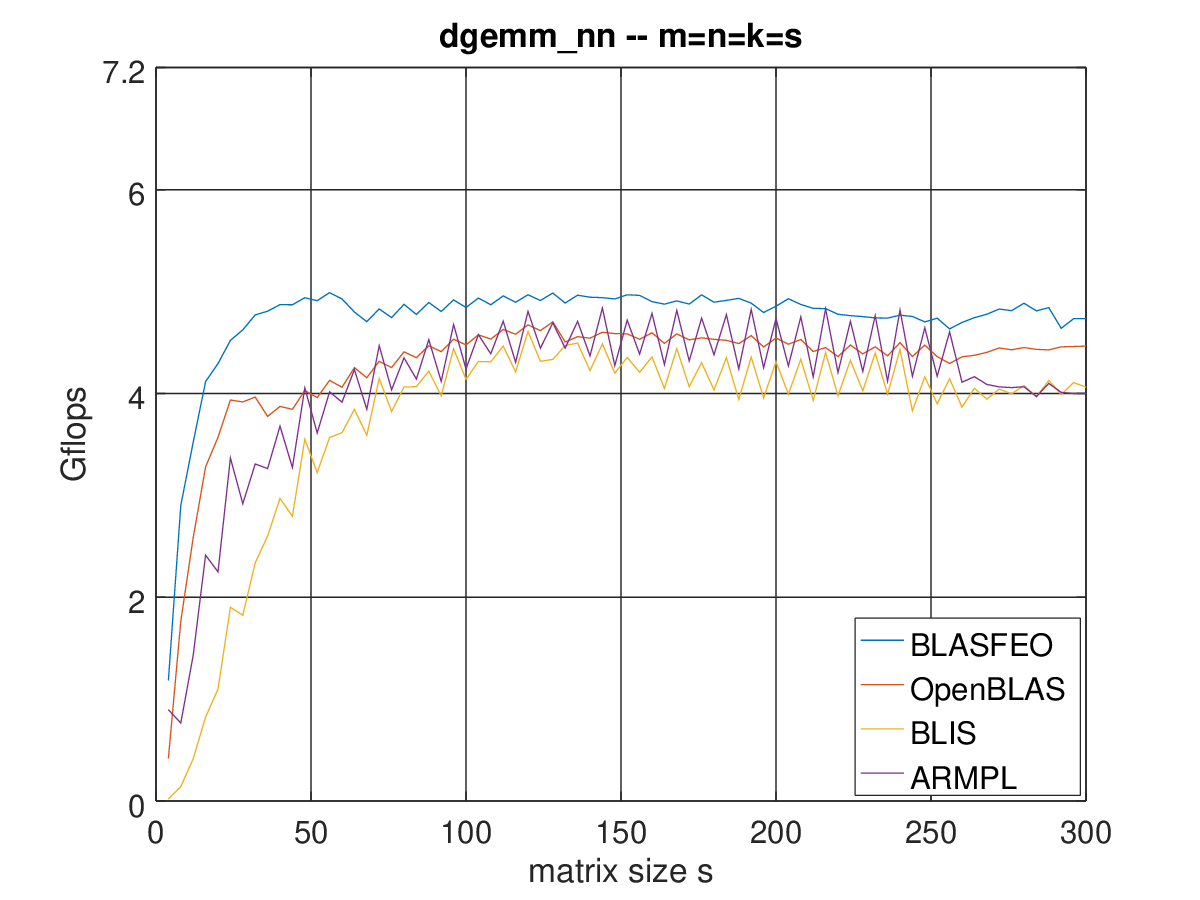
About the benchmark you mention, there are a few things to be noted. To start with, it is a multi threaded benchmark with 64 threads, while BLASFEO is single threaded (ATM). Then, BLIS is known to be really particularly bad for small matrices (to the point of being rather unusable for our kind of applications, being much slower than trivial triple-loop-based linear algebra; this has recently changed for selected architectures (Haswell) and routines (gemm)), rather than ARMPL being particularly good for small matrices. Actually, BLASFEO generally outperforms single-threaded ARMPL for small matrices.
In any case, yes, you can compile BLASFEO with the LA=EXTERNAL_BLAS_WRAPPER backend https://github.com/giaf/blasfeo/blob/master/Makefile.rule#L123 which is simply a wrapper to whatever BLAS and LAPACK you want to provide. At that point you simply need to completely clean and recompile HPIPM and acados linking to this BLASFEO version (and relative header files which define how the BLASFEO matrix structure actually looks like in memory, and which are different for different LA backends) and to the BLAS/LAPACK implementation of your choice.
I hope I could satisfactorily answer to your questions.