I want to build ACADOS together with HPIPM and BLASFEO on a Drive PX 2 with Ubuntu 16.04. Using cmake without additional arguments and make afterwards succeeds. As far as I understood this results in a generic BLASFEO build without optimizations for the target hardware. The Drive PX 2 contains Nvidia Denver2 ARMv8 (64-bit) dual-core and ARMv8 ARM Cortex-A57 quad-core (64-bit) CPUs. Therefore, I tried to optimize the build for the Cortex A57:
nvidia@tegra-ubuntu:~/Programs/acados/build$ cmake … -DBLASFEO_TARGET=ARMV8A_ARM_CORTEX_A57
– The C compiler identification is GNU 5.4.0
– The CXX compiler identification is GNU 5.4.0
– Check for working C compiler: /usr/bin/cc
– Check for working C compiler: /usr/bin/cc – works
– Detecting C compiler ABI info
– Detecting C compiler ABI info - done
– Detecting C compile features
– Detecting C compile features - done
– Check for working CXX compiler: /usr/bin/c++
– Check for working CXX compiler: /usr/bin/c++ – works
– Detecting CXX compiler ABI info
– Detecting CXX compiler ABI info - done
– Detecting CXX compile features
– Detecting CXX compile features - done
– Build type is Release
– ACADOS_WITH_OPENMP: OFF
– The ASM compiler identification is GNU
– Found assembler: /usr/bin/cc
– Using linear algebra: HIGH_PERFORMANCE
– Using external BLAS: 0
– Testing target ARMV8A_ARM_CORTEX_A57: assembly compilation [success]
– Testing target ARMV8A_ARM_CORTEX_A57: assembly run [success]
– Testing target ARMV8A_ARM_CORTEX_A57: intrinsic compilation [success]
– Testing target ARMV8A_ARM_CORTEX_A57: intrinsic run [success]
– Compiling for target: ARMV8A_ARM_CORTEX_A57
– Using BLASFEO path:
– Installation directory: /home/nvidia/Programs/acados
–
– Target: BLASFEO is ARMV8A_ARM_CORTEX_A57, HPIPM is X64_AUTOMATIC
– Linear algebra: HIGH_PERFORMANCE
– Matlab MEX (OFF)
– Octave MEX (OFF)
– Octave Templates (OFF)
– System name:version Linux:4.9.80-rt61-tegra
– Build type is Release
– Installation directory is /home/nvidia/Programs/acados
– OpenMP parallelization is OFF
–
– Configuring done
– Generating done
– Build files have been written to: /home/nvidia/Programs/acados/build
So far, so good: cmake seems to work, but unfortunately make fails:
nvidia@tegra-ubuntu:~/Programs/acados/build$ make
Scanning dependencies of target blasfeo
[ 0%] Building C object external/blasfeo/CMakeFiles/blasfeo.dir/auxiliary/blasfeo_processor_features.c.o
[ 1%] Building C object external/blasfeo/CMakeFiles/blasfeo.dir/auxiliary/blasfeo_stdlib.c.o
[ 1%] Building C object external/blasfeo/CMakeFiles/blasfeo.dir/auxiliary/d_aux_lib4.c.o
[ 1%] Building C object external/blasfeo/CMakeFiles/blasfeo.dir/auxiliary/s_aux_lib4.c.o
[ 2%] Building C object external/blasfeo/CMakeFiles/blasfeo.dir/auxiliary/m_aux_lib44.c.o
[ 2%] Building ASM object external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dgemm_8x4_lib4.S.o
[ 3%] Building ASM object external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dgemm_4x4_lib4.S.o
[ 3%] Building ASM object external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dpack_lib4.S.o
[ 4%] Building ASM object external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dgemv_4_lib4.S.o
/home/nvidia/Programs/acados/external/blasfeo/kernel/armv8a/kernel_dgemv_4_lib4.S: Assembler messages:
/home/nvidia/Programs/acados/external/blasfeo/kernel/armv8a/kernel_dgemv_4_lib4.S:1190: Error: unknown mnemonic inner_blend_t_4_lib4' -- inner_blend_t_4_lib4’
external/blasfeo/CMakeFiles/blasfeo.dir/build.make:233: recipe for target ‘external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dgemv_4_lib4.S.o’ failed
make[2]: *** [external/blasfeo/CMakeFiles/blasfeo.dir/kernel/armv8a/kernel_dgemv_4_lib4.S.o] Error 1
CMakeFiles/Makefile2:246: recipe for target ‘external/blasfeo/CMakeFiles/blasfeo.dir/all’ failed
make[1]: *** [external/blasfeo/CMakeFiles/blasfeo.dir/all] Error 2
Makefile:138: recipe for target ‘all’ failed
make: *** [all] Error 2
thanks for the report, there was a bug in a routine in the BLASFEO version optimized for Cortex A57.
Now I fixed the bug and updated the BLASFEO version used in acados, so just pull & try again.
BTW, I never got access to a NVIDIA Denver2 core, so I would be curious to see how BLASFEO performs there (and more in general how the core performs compared to the Cortex A57).
If you are up for it, I can point you to a couple of benchmarks in BLASFEO to find it out.
thanks for the fix. I probably have access to the machine at the end of the week and let you know if it works. Then I can also execute some benchmarks if you want. I guess you mean the benchmarks folder in blasfeo-root?
By the way: HPIPM does not have any hardware optimizations except for Intel/AVX, right?
about HPIPM, all expensive operations (matrix-vector and matrix-matrix) are performed with BLASFEO calls, so what is left are only vector-vector operations. It makes sense to look into vectorizing them too only on powerful enough computer architectures / wide enough vectors (see Amdahl’s law), that’s why I only did for AVX, and already in this case the speed up is very small (maybe in the order of single digit percent).
So on currently available ARM microarchitectures GENERIC is a good target in HPIPM.
About the benchmarks in BLASFEO, yes it would be a matter of working in the BLASFEO main folder itself. Here are the steps (for the make build system, the cmake probably doesn’t have all benchmarks implemented atm; and I assume linux OS):
Compile BLASFEO for the Cortex A57 target, with MF=PANELMAJ and BLAS_API=1.
You may want to use taskset to select the specific CPU to run on using a bit-mask (e.g. taskset 1 make run_benchmarks will run on CPU 0, while taskset 4 make run_benchmarks will run on CPU 2).
This should be enough for be to get a feeling of the NVIDIA Denver CPU capabilities.
Then if you want to investigate different routines or ranges, now you know how to do it
Finally, you could try to run your entire application on the Cortex A57 and Denver, to check which one performs better (this is not always perfectly correlated to the optimized linear algebra performance).
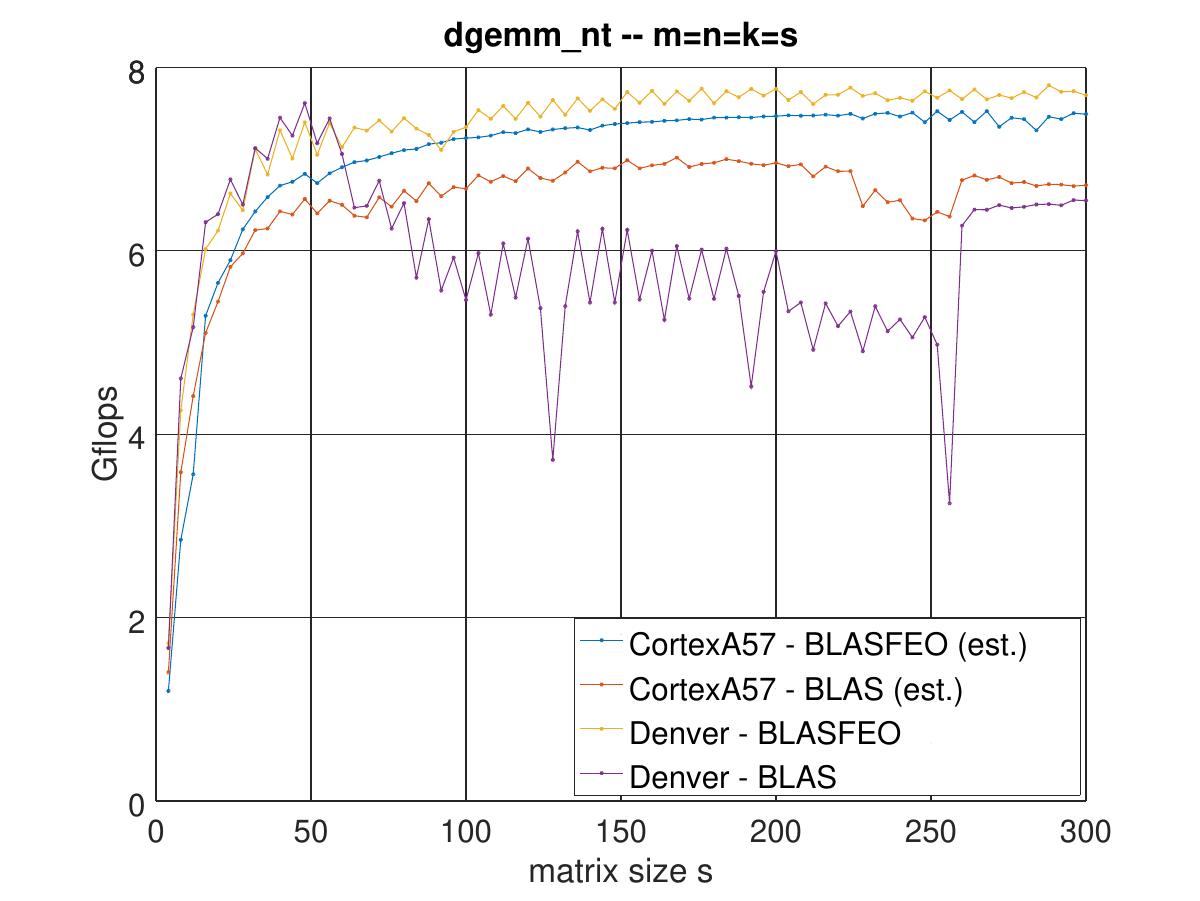
I finally had some time to process the data.
I think the benchmarks were indeed run on the Denver CPU, as the behavior looks quite different compared to the Cortex A57 in my Tegra TX1.
Here are some figures (where the Cortex A57 data are estimates from my 2.15 GHz Tegra TX1, where I scaled the results down to estimate a 2.0 GHz frequency).
In summary, Denver seems to have slightly better higher performance if data fits in L1 cache, but it appears to have weaker prefetchers and/or worse cache associativity, which affects performance if data is not in L1 cache, especially if the data access is not perfectly sequential.
All in all, in a more complex workload such as in acados the performance should be quite close for Denver and Cortex A57, with maybe the Cortex A57 performing a bit better.
You could try it out and check if indeed a Cortex A57 core is the best choice to run acados on the Nvidia Drive PX2.